Grace Hopper answers, "Why does it take so damn long to send a message by satellite?" Specifically she does a tremendous job of visualizing the difference between a nanosecond and a microsecond, and what it means to throw away microseconds of computing time.
I am a computational biologist. Sometimes I use computers to compare differences and similarities between the nucleotides (A's, T's, G's and C's) of mammalian genomes. Sometimes I look at evolution of the human sex chromosomes. I always write computer programs to analyze these datasets.
New technology means that the size of the datasets that we can produce is increasing, and will continue to increase during my lifetime. Computational infrastructure has also been increasing (see a history of computer storage). But, computational power and storage is not going to scale fast enough to keep pace with the size and complexity of the datasets we will need to analyze. That's why Hopper's video above is so relevant.
I've noticed a mentality in biology circles that all we need to do to be able to analyze larger and larger datasets is to increase computing power. But, there are some big problems with this:
1. Computers are not self-sustaining.
Computers need to be maintained, cooled, managed, and cared for. Computing resources need a space where they will be kept cooled. Computers cannot upload or update their own software. Computers cannot turn themselves back on after a power outage, back themselves up (without instructions to do so), or upgrade their own hard drives.
We need good system administrators, and computational lab managers, to maintain computing resources, and these people need to be paid a competitive salary. High-performace computers is not a once-and-done expenditure; it is an investment.
2. Bigger is not enough.
Yes, large datasets do require lots of storage space, and analysis will increase with faster processors, but that isn't enough. Let's think about it this way:
Imagine I have a dataset that takes one week of computing time to analyze using my fast processors, all of the storage I need, and my current code. If my dataset grows to be a hundred times larger, my dataset will now take 100 weeks of computing time to analyze. If I take no time to optimize my code, or parallelize the jobs, or figure out a new, faster, method, I will be waiting two years (assuming no hiccups) just to see what the new results are.
That is unacceptable. We need to code smarter. Similarly, we need to utilize efficient storage formats. There is progress in this direction, but it needs to be a constant focus.
3. Open science.
Despite the wonders of the internet, I would argue that most of us do not take the time to carefully edit and annotate our code, and make it publicly available to others. This is especially true for all of the "in-house" scripts used for data processing. These are small scripts that aren't stand-alone programs for some new type of analysis, just day-to-day analyses or parsers. But without these intermediate scripts an outside person cannot replicate our analysis exactly. I'm guilty of this myself. I do try to comment my codes heavily, and I locally archive all the codes for each project, but I don't always go the extra step of archiving them somewhere *public*. Going forward I am going to change this.
One option is to create a pipeline of all scripts with a clear README file, and deposit into public repositories like GitHub. Another is to incorporate tools into a web-based platform that allows workflows, like Galaxy. A third option is to maintain the code on a local website, but this seems more like a back-up to me.
Grace Hopper chastised programmers for not appreciating the value of a microsecond. Her admonition rings true as much today as it did over 20 years ago.
Thursday, January 30, 2014
Sunday, January 26, 2014
Notes on: Single-cell RNA-Seq reveals dynamic, random monoallelic gene expression in mammalian cells
Brief background:
We have two copies of each non-sex gene. Each version of the gene is called an allele: one inherited from your genetic mother, one from your genetic father. It is generally thought that each allele is expressed (turned out) at the same intensity. But, there are some examples where this isn't true. The most notable occurs on the X chromosome. Females with two X chromosomes inherited one X chromosome from each parent, but one of these X chromosomes is almost completely inactivated. That means that instead of having biallelic expression (expression from both the maternal and paternal allele), most genes on the X chromosome exhibit monoallelic expression.
In recent work, Deng et al (2014) isolated single cells from two different stains of mice, where they could detect maternal-alleles and paternal-alleles for over 82% of assayed genes (in the other genes, there were not unique variants that allowed deciphering between the two alleles). For each gene, the authors characterized whether they could detect expression from both the maternal and paternal alleles, or from only the maternal or paternal allele. Although the title says, "mammalian," all of the experiments and analysis were conducted in mouse cells and tissues, so far as I can tell.
My notes and thoughts on the paper:
Here is the Storify of the discussion on twitter about this result, and how it is transcriptional bursting. I wasn't aware of the term, so here's the wikipedia entry for transcriptional bursting. Given this background, it is not so surprising that there is so much variation in expression across the autosomes, but my questions about what kind of classes exhibit measurable levels of this phenomenon in single cells still stands.
Also, I did focus on the X chromosome results because to me they were the most interesting. In marsupials it is always the paternal X that is inactivated - there is no random X-inactivation. My understanding is that in eutherian mammals the paternal X is inherited as inactivated, it is reactivated, then either the maternal or paternal allele is randomly inactivated. That said, there is some evidence of preferential paternal X-inactivation in mice - see Paternally biased X inactivation in mouse neonatal brain.
We have two copies of each non-sex gene. Each version of the gene is called an allele: one inherited from your genetic mother, one from your genetic father. It is generally thought that each allele is expressed (turned out) at the same intensity. But, there are some examples where this isn't true. The most notable occurs on the X chromosome. Females with two X chromosomes inherited one X chromosome from each parent, but one of these X chromosomes is almost completely inactivated. That means that instead of having biallelic expression (expression from both the maternal and paternal allele), most genes on the X chromosome exhibit monoallelic expression.
In recent work, Deng et al (2014) isolated single cells from two different stains of mice, where they could detect maternal-alleles and paternal-alleles for over 82% of assayed genes (in the other genes, there were not unique variants that allowed deciphering between the two alleles). For each gene, the authors characterized whether they could detect expression from both the maternal and paternal alleles, or from only the maternal or paternal allele. Although the title says, "mammalian," all of the experiments and analysis were conducted in mouse cells and tissues, so far as I can tell.
My notes and thoughts on the paper:
- The authors state, "…different SNPs within the same gene gave coherent allelic calls (fig. S2)." I am very interested to see what they did in cases where different SNPs did not give the same estimates of allele-specific expression.
- Mouse paternal X chromosome inactivation is complicated. In single cells, the paternal X chromosome is inactive initially, reactivated starting at the late 2-cell stage, active at the 4-cell stage, then inactivated starting at the 16-cell stage, and completely inactivated again by the early blastocyst stage. Xist appears to be off during early embryogensis, and is only expressed starting at the 16-cell stage - correlating with the re-silencing of the paternal X chromosome in the mouse.
- X-inactivation near and far from mouse XIC. The spread of X-inactivation is not directly correlated to the distance from the X-inactivation center (XIC).
- Technology biases estimates of allele-specific expression. Initial observations of allele-specific expression on the autosomes suggested over half of all genes exhibit mono-allelic expression, but as much as 66% of these are false positives due to the loss of RNA molecules with the available technology. After inferring the proportion of losses RNA molecules, the authors propose that 12-24% of genes exhibit monoallelic expression in single cells.
- Monoallelic expression evens out in tissues. The authors state, "Pooling cells by embryo removed essentially all monoallelic expression, demonstrating a high degree of cell-specific randomness in monoallelic expression." To me this suggests that studies of single cell gene expression may not give the most accurate picture of gene expression within a tissue.
Additional thoughts:
- I would very much like to know how estimates of allele-specific expression on the X chromosome varied between the single cell and multicelluar analyses.
- The authors claim the patterns of monoallelic expression on the autosomes is likely due to independent allelic expression, but I would like to understand the mechanism more. Is this simply variance in polymerase activity?
- If 12-24% of genes are expressed from only one allele, what can we learn from it? Is dosage of these genes less important? Is selection weaker on genes that are more likely to be mono-allelicly expressed?
Science. 2014 Jan 10;343(6167):193-6. doi: 10.1126/science.1245316.
Single-cell RNA-seq reveals dynamic, random monoallelic gene expression in mammalian cells.
---------------------------------------------------------------------------------------------------
Update:Here is the Storify of the discussion on twitter about this result, and how it is transcriptional bursting. I wasn't aware of the term, so here's the wikipedia entry for transcriptional bursting. Given this background, it is not so surprising that there is so much variation in expression across the autosomes, but my questions about what kind of classes exhibit measurable levels of this phenomenon in single cells still stands.
Also, I did focus on the X chromosome results because to me they were the most interesting. In marsupials it is always the paternal X that is inactivated - there is no random X-inactivation. My understanding is that in eutherian mammals the paternal X is inherited as inactivated, it is reactivated, then either the maternal or paternal allele is randomly inactivated. That said, there is some evidence of preferential paternal X-inactivation in mice - see Paternally biased X inactivation in mouse neonatal brain.
Tuesday, January 21, 2014
Thursday, January 16, 2014
Accessible research: Natural selection reduced diversity on human Y chromosomes
We just had a paper published over at PLoS Genetics entitled, "Natural selection reduced diversity on human Y chromosomes." But, as you may recall, it has been available on the arXiv for quite some time.
Others have already summarized the work (Razib Khan nails the punchline, and Ian Sample has a summary for the popular press).
Below are answers to many of the questions I received about this work.
The human sex chromosomes, X and Y, used to be nearly identical, but now the Y has lost 90% of the genes it once shared with the Y, and some have speculated that the Y chromosome will disappear in less than five million years. We show that human Y chromosomes are much more similar to each other than expected. Previously, variance in male reproductive success (meaning some men fathering many children, and some men fathering few or none), was thought to explain this similarity, but we show that an additional force, natural selection, is needed to reduce diversity across Y chromosomes to the levels we observe.
Could you briefly explain how exactly you showed that variation on the Y chromosome is consistent with natural selection? What does this mean?
We first ran statistical models that let us alter the number of males and females that contributed their genomes (the non-sex chromosomes, chromosome X, chromosome Y, and mtDNA) to the next generation. We reduced the proportion of males passing on their genomes to the next generation in a series of experiments, but in doing so, the modeled estimates of variation in the genome did not match the observed levels of variation.
We next developed statistical models to estimate the number of sites affected by purifying selection on a set of hypothetical Y chromosomes, then tested which models were most likely to have acted in the past, given what the variation we observe across the genome today. Purifying selection removes, or purifies out, harmful mutations. It can also affect linked neutral sites. However, everything on the Y chromosome is linked together, so selection acting anywhere on the Y-specific portion of the Y chromosome will remove variation across the entire chromosome.
We found that, accounting for population-specific variation in male reproductive success (boxed results below), the number of sites predicted to be affected by purifying selection on the human Y chromosome fell in between the number of single-copy coding sites and the total number of sites in the ampliconic regions.
This means that in addition to the single-copy coding genes on the Y chromosome, the highly repetitive, but still poorly understood, ampliconic regions are likely also affected by natural selection.
Purifying selection - that removes harmful mutations - acting on many sites of the Y chromosome, resulted in a population of Y chromosomes as similar to one another as the the Y chromosomes we observed in the real human data.
What can you say about the function of the 27 genes located on the Y chromosome. What do you know about the ampliconic regions?
Although not part of this study, I can say that the 27 genes on the Y chromosome can generally be divided into those that function in many tissues, and those that now primarily function in the testes. The ampliconic genes are only turned on in the testes. Both these groups appear to have major roles in sperm motility and function.
What can your research tell us about our ancestor’s history. How does it change the picture?
When we think about the population of our common ancestors, what this tells us is that, although there has certainly been variation in male reproductive success, and that this varies across populations, the genes on the Y chromosome continue to be preserved because they serve an important function. It also tells us that estimates of the time to the most recent common ancestor of the Y chromosome might be underestimates if purifying selection has been a constant force, reducing diversity on the Y chromosome.
Certainly there is variation across human populations. In some populations, variation in male reproductive success will have a stronger impact. For example, I look forward to extending these results to see whether the Y chromosomes of Central Asian populations, with the genetic legacy of Genghis Khan, might show more of an effect of variance in male reproductive success.
What makes the sex chromosome history so fascinating for you?
Everything! I am amazed at how the X and Y used to be nearly identical, just like any of our non-sex-chromosomes, and yet today the Y has lost 90% of the ancestral gene content, and both X and Y have accumulated sex-specific elements. I want to understand why these chromosome became so different in some lineages but not others, how this process is shaped by population history, what unique role these chromosomes play in health, and where we can expect them to go in the future. See other posts on sex chromosomes in emus, spiny rats, and in the plant, Silene latifolia.
Can you give me some examples of mammals that already lost their Y chromosome?
The Okinawa spiny rat. However, it is unfair to say it completely lost its Y chromosome. What we think happened is that a few of the genes on the Y chromosome (or at least the sex-determining gene) jumped to a non-sex chromosome pair. In some Okinawa spiny rats, it was recently discovered that the degraded Y chromosome fused to a non-sex chromosome pair. This new location, although we haven't identified it yet, will now evolve into the next sex chromosome pair.
We find complementary roles between variance in male reproductive success, and selection, in shaping the pattern of variation on the human Y chromosomes. It will be fascinating to assess this in more human populations, to see how local environments have uniquely shaped the evolution of the Y chromosome.
Others have already summarized the work (Razib Khan nails the punchline, and Ian Sample has a summary for the popular press).
Below are answers to many of the questions I received about this work.
How would you describe the importance of your findings?
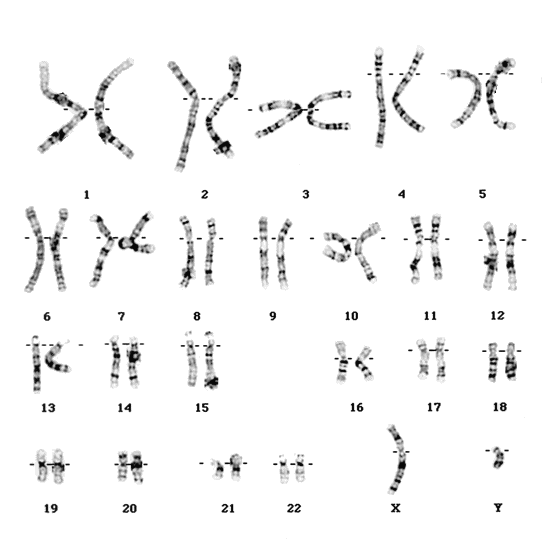 |
| Human chromosomes by Paquete |
Could you briefly explain how exactly you showed that variation on the Y chromosome is consistent with natural selection? What does this mean?
We first ran statistical models that let us alter the number of males and females that contributed their genomes (the non-sex chromosomes, chromosome X, chromosome Y, and mtDNA) to the next generation. We reduced the proportion of males passing on their genomes to the next generation in a series of experiments, but in doing so, the modeled estimates of variation in the genome did not match the observed levels of variation.
 |
| Here none of the grey-scale bars match all of the green bars |
We next developed statistical models to estimate the number of sites affected by purifying selection on a set of hypothetical Y chromosomes, then tested which models were most likely to have acted in the past, given what the variation we observe across the genome today. Purifying selection removes, or purifies out, harmful mutations. It can also affect linked neutral sites. However, everything on the Y chromosome is linked together, so selection acting anywhere on the Y-specific portion of the Y chromosome will remove variation across the entire chromosome.
We found that, accounting for population-specific variation in male reproductive success (boxed results below), the number of sites predicted to be affected by purifying selection on the human Y chromosome fell in between the number of single-copy coding sites and the total number of sites in the ampliconic regions.
 |
| Maximum likelihood estimates of chrY sites affected by purifying selection. |
Purifying selection - that removes harmful mutations - acting on many sites of the Y chromosome, resulted in a population of Y chromosomes as similar to one another as the the Y chromosomes we observed in the real human data.
Were you surprised to find what you uncovered?
We were surprised to see how much of the Y chromosome is affected by selection. Here we show that at least some of the the highly repetitive ampliconic regions (so called because they are amplified in copy number) are acted on by selection. These regions are necessary for sperm formation and function, but are poorly studied because of how difficult it is to sequence them. Our results suggest that we need more investment into studying the most challenging parts of our genome.
What can you say about the function of the 27 genes located on the Y chromosome. What do you know about the ampliconic regions?
 |
| Y-linked genes help sperm form and swim. |
Although not part of this study, I can say that the 27 genes on the Y chromosome can generally be divided into those that function in many tissues, and those that now primarily function in the testes. The ampliconic genes are only turned on in the testes. Both these groups appear to have major roles in sperm motility and function.
What can your research tell us about our ancestor’s history. How does it change the picture?
When we think about the population of our common ancestors, what this tells us is that, although there has certainly been variation in male reproductive success, and that this varies across populations, the genes on the Y chromosome continue to be preserved because they serve an important function. It also tells us that estimates of the time to the most recent common ancestor of the Y chromosome might be underestimates if purifying selection has been a constant force, reducing diversity on the Y chromosome.
 |
| Portrait of Genghis Khan |
What makes the sex chromosome history so fascinating for you?
Everything! I am amazed at how the X and Y used to be nearly identical, just like any of our non-sex-chromosomes, and yet today the Y has lost 90% of the ancestral gene content, and both X and Y have accumulated sex-specific elements. I want to understand why these chromosome became so different in some lineages but not others, how this process is shaped by population history, what unique role these chromosomes play in health, and where we can expect them to go in the future. See other posts on sex chromosomes in emus, spiny rats, and in the plant, Silene latifolia.
Can you give me some examples of mammals that already lost their Y chromosome?
The Okinawa spiny rat. However, it is unfair to say it completely lost its Y chromosome. What we think happened is that a few of the genes on the Y chromosome (or at least the sex-determining gene) jumped to a non-sex chromosome pair. In some Okinawa spiny rats, it was recently discovered that the degraded Y chromosome fused to a non-sex chromosome pair. This new location, although we haven't identified it yet, will now evolve into the next sex chromosome pair.
In what ways do these results present a step forward in the debate on whether or not the Y chromosome is more or less dispensable?
Our findings suggest that natural selection is acting strongly on the human Y chromosome, and it is unlikely to disappear any time soon - you can call me on this in 5 million years if I'm wrong.
Why is there still so little coverage of the Y chromosome in genome sequencing?
It isn't so much that there is so little coverage of the Y chromosome, but that most projects do not assemble the reads they have from the Y chromosome, and there's a good reason for this - most of it is a mess! With the current technology, the length of pieces of DNA (usually 100-200 nucleotides) to look at from genome sequencing are too short to get a good handle on many of the highly repetitive regions of the Y chromosome. With new advances in technology, or with a lot of time and diligence using more involved techniques (such as single haplotype iterative mapping and sequencing, SHIMS), we will learn more about these difficult to study regions of the Y chromosome.
How do your findings fit into recent research in mice that only two genes on the Y chromosome are necessary to produce offspring? Even though the Y might not disappear it seems to be superfluous soon.
The mouse Y chromosome work showed that by using twoY-specific genes, SRY, and Eif2S3Y, mice would develop with male characteristics and would produce immature sperm (it isn’t clear if they could develop fully functional sperm). In this case, I can say that the trajectory of the primate, specifically the human, Y chromosome and the mouse Y chromosome are very different. The similarity with humans is that SRY is also one of the main regulators of pathways that turn on testes formation, but a big difference is that the second gene, Eif2S3Y, is broken in humans. Furthermore, the mouse Y chromosome is pretty wimpy, in gene content, compared to the human Y. The human Y has retained many more genes from the ancestral mammalian sex chromosome, and many of these have been shown to function in sperm formation and motility, so it seems like it will be much for difficult for fertile, sperm-producing humans to develop without a Y chromosome. Furthermore, while many of the human Y-linked genes are involved in male-specific functions, there are several that are turned on in other tissues, such as the brain, and liver, so it seems unlikely there are more genes that are involved in form and function on the human Y than the mouse Y. That said, there are humans who have a single X chromosome and no partner X or Y (this is called Turner syndrome), suggesting that fertilization is a resilient process.
What do you think might be the most important aspect of your research? How can it be used in the future? What are your next steps?
One of the most important aspects will be understanding whether positive selection has also played a strong role in shaping human Y chromosome diversity. We did not have the power to detect a difference between purifying selection (which acts to remove harmful mutations) and positive selection (which acts to increase a beneficial mutation in frequency), but plan to look at this in the future as more Y chromosomes are sequenced.
Is there anything you might want to add or stress concerning your studies?
It isn't so much that there is so little coverage of the Y chromosome, but that most projects do not assemble the reads they have from the Y chromosome, and there's a good reason for this - most of it is a mess! With the current technology, the length of pieces of DNA (usually 100-200 nucleotides) to look at from genome sequencing are too short to get a good handle on many of the highly repetitive regions of the Y chromosome. With new advances in technology, or with a lot of time and diligence using more involved techniques (such as single haplotype iterative mapping and sequencing, SHIMS), we will learn more about these difficult to study regions of the Y chromosome.
How do your findings fit into recent research in mice that only two genes on the Y chromosome are necessary to produce offspring? Even though the Y might not disappear it seems to be superfluous soon.
 |
| MRI of human head |
What do you think might be the most important aspect of your research? How can it be used in the future? What are your next steps?
One of the most important aspects will be understanding whether positive selection has also played a strong role in shaping human Y chromosome diversity. We did not have the power to detect a difference between purifying selection (which acts to remove harmful mutations) and positive selection (which acts to increase a beneficial mutation in frequency), but plan to look at this in the future as more Y chromosomes are sequenced.
Is there anything you might want to add or stress concerning your studies?
We find complementary roles between variance in male reproductive success, and selection, in shaping the pattern of variation on the human Y chromosomes. It will be fascinating to assess this in more human populations, to see how local environments have uniquely shaped the evolution of the Y chromosome.
Wednesday, January 15, 2014
Scientist parent
You know what makes it hard being a woman in science? These attitudes:
1. Yesterday I read this comment from a friend:
Let's start with the first, shall we?
No, it is not impossible to be a rock star career woman and rock star mom.
I think this is a false dichotomy that gets fed to women. It isn't about choosing one over the other, but finding a career, and a way of parenting, that lets you succeed at both. That doesn't mean it is easy, or that it is the right choice for everyone. It may also mean acknowledging that cultural expectations of rockstar parenting (especially for mothers) are unrealistic, and that you may never reach global rockstar scientist status, even if you put every waking moment into it.
Rockstar parent
In my mind, being a rockstar parent is not about making all the cutesy kid activities, but spending real time with my daughter. I see plenty of stay-at-home parents who spend less time actually interacting with their children than I do (granted, there are others who truly take advantage of the opportunity). I answer questions, we explore and play together. My daughter comes before work. Sometimes that means a lot of work happens after hours, but it means that the time we spend together is quality time.
Rockstar scientist
There are scientists who do half the work I do, without family obligations, pissing away the day chatting to everyone, and bypassing opportunities that come up. Am I as social as everyone in the lab? No, but that isn't what being a rockstar scientist is about - it's about doing good research and getting it out. Could I publish more if I weren't a parent? I don't know. I've published more as a postdoc, with a child, than I did before my daughter was born. I've been lucky to get independent funding for my research, and even gotten some publicity for my research. For me there are only so many hours I can be productive in a row, which means that dividing up my working time into different sections of my day is how I'd work with or without a child.
Fewer women because babies
And then we have half-witted comments like the "correspondence" Nature editors thought would be a good idea to publish. It's hard not to quote the whole thing, but here's one section, by Lukas Koube:
So, women are too busy babying (y'know, because those are the only people who raise offspring these days), to be productive, ergo, there really is no gender inequity in science. Never mind all the women who don't have children, or those of us who manage to do both. And never mind the research that shows female applicants are ranked lower than equally qualified male applicants. And never mind that letters of recommendation are implicitly biased against female applicants. Let's just say that my conclusion was that this comment was printed because one of the editors wanted to say it, but wanted someone else to get the blame for saying it.
Chopped liver?
Every time I see someone post about how we have to choose between being good scientists and being good parents, or suggesting that we can blame those lazy women for gender inequality because they're too busy babying, I feel my chest tighten, and I just want to scream: "So what the hell am I? Do you think I'm a failure as a scientist? Do you think I am a terrible parent? Am I not productive enough for you? Am I not doting enough for you?"
If we identify aspects that make sciencing while parenting challenging, let's address these, support each other, and develop policies to help people do both well. And why so much judgement instead of just observing that, miraculously, parents, even women, have been able to science good, and parent good. At the same time.
1. Yesterday I read this comment from a friend:
This reminds me of the conclusion many of us have faced: that it's impossible to be a rock star career woman while being a rock star mom.
"If you chase two rabbits, you will not catch either one - Russian Proverb"2. And today, this correspondence in Nature. It's short, but the shorter summary is this: There's no gender bias in science, and if there is, it's because women are busy having babies.
Let's start with the first, shall we?
No, it is not impossible to be a rock star career woman and rock star mom.
I think this is a false dichotomy that gets fed to women. It isn't about choosing one over the other, but finding a career, and a way of parenting, that lets you succeed at both. That doesn't mean it is easy, or that it is the right choice for everyone. It may also mean acknowledging that cultural expectations of rockstar parenting (especially for mothers) are unrealistic, and that you may never reach global rockstar scientist status, even if you put every waking moment into it.
Rockstar parent
In my mind, being a rockstar parent is not about making all the cutesy kid activities, but spending real time with my daughter. I see plenty of stay-at-home parents who spend less time actually interacting with their children than I do (granted, there are others who truly take advantage of the opportunity). I answer questions, we explore and play together. My daughter comes before work. Sometimes that means a lot of work happens after hours, but it means that the time we spend together is quality time.
Rockstar scientist
There are scientists who do half the work I do, without family obligations, pissing away the day chatting to everyone, and bypassing opportunities that come up. Am I as social as everyone in the lab? No, but that isn't what being a rockstar scientist is about - it's about doing good research and getting it out. Could I publish more if I weren't a parent? I don't know. I've published more as a postdoc, with a child, than I did before my daughter was born. I've been lucky to get independent funding for my research, and even gotten some publicity for my research. For me there are only so many hours I can be productive in a row, which means that dividing up my working time into different sections of my day is how I'd work with or without a child.
Fewer women because babies
And then we have half-witted comments like the "correspondence" Nature editors thought would be a good idea to publish. It's hard not to quote the whole thing, but here's one section, by Lukas Koube:
Having young children may prevent a scientist from spending as much time publishing, applying for grants and advancing their career as some of their colleagues. Because it is usually women who stay at home with their children, journals end up with more male authors on research articles. The effect is exacerbated in fast-moving fields, in which taking even a year out threatens to leave a researcher far behind.
So, women are too busy babying (y'know, because those are the only people who raise offspring these days), to be productive, ergo, there really is no gender inequity in science. Never mind all the women who don't have children, or those of us who manage to do both. And never mind the research that shows female applicants are ranked lower than equally qualified male applicants. And never mind that letters of recommendation are implicitly biased against female applicants. Let's just say that my conclusion was that this comment was printed because one of the editors wanted to say it, but wanted someone else to get the blame for saying it.
Chopped liver?
Every time I see someone post about how we have to choose between being good scientists and being good parents, or suggesting that we can blame those lazy women for gender inequality because they're too busy babying, I feel my chest tighten, and I just want to scream: "So what the hell am I? Do you think I'm a failure as a scientist? Do you think I am a terrible parent? Am I not productive enough for you? Am I not doting enough for you?"
If we identify aspects that make sciencing while parenting challenging, let's address these, support each other, and develop policies to help people do both well. And why so much judgement instead of just observing that, miraculously, parents, even women, have been able to science good, and parent good. At the same time.
Tuesday, January 14, 2014
Science and parenting can complement each other.
I love doing science. I also love being a parent. Yes, parenting does take up time that I could otherwise spend doing science (as do things like, grocery shopping, eating, and, having a life outside of lab). But, as a scientist, my brain is never totally turned off to science. And that is one of the reasons I knew I wanted to go into science. I see science everywhere. I question everything (which can sometimes be frustrating to those around me). I always have. Being a parent lets me expand my world, questioning so many things that I might have previously overlooked. Being a parent forces me to step outside of the small slice of science I've carved out for myself.
As a parent, I admit when I don't know the answer, and try to use it as an opportunity to figure out the answer together.
We read a lot. Books bring up so many questions - What are they doing? What is that? How does that work? Really, reading leads to endless questions. También es una oportunidad para aprender y practicar Español.
The local library has a whole floor dedicated to kids that includes books, and an area for the younger kids to play. I like how the children's floor mixes play with books. We play a bit, then take a break to read a book. I am of the firm opinion that we can never have too many books at home, but it is nice to borrow books from the library, and not wonder where we're going to store them all.
I use my imagination more now than I have in a long time. At home, or out, I am surprised by how creative developing minds can be, and how quickly my mind can jump in too! I just learned that one of the games the kids play at daycare is "watching television", where they all sit in a semi-circle, staring at the blank wall (there's no television at daycare), pointing and laughing, and describing to each other what they're seeing. Now that is imagination.
As a parent, I admit when I don't know the answer, and try to use it as an opportunity to figure out the answer together.
We read a lot. Books bring up so many questions - What are they doing? What is that? How does that work? Really, reading leads to endless questions. También es una oportunidad para aprender y practicar Español.
 |
| Finding goldbug together. |
 |
| Taking turns piloting the paintbrush rocket at the Downtown Berkeley library. |
We live in an apartment without a backyard and just a very small shared green space, but try to spend a lot of time outside, at the playground nearby, or hiking, or various parks in the area. We keep our eyes peeled for wee beasties of all sorts (lizards, spiders, millipedes, ants, voles, birds, etc).
|
 |
| You can never be too safe when blowing bubbles. |
 |
| Playing in a "pool" at the park. |
Sometimes I wish I had more time at home. Sometimes I wish I had more time at work. Usually, however, I really enjoy my time working, and I really enjoy my time with my family. To me this means that I find fulfillment in my work and in my family life. I hope this is always the case.
Thursday, January 9, 2014
Free Registration: Berkeley Cancer Genomics Symposium
Online registration for the Berkeley Cancer Genomics Symposium has been extended to Monday, January 13; to register visit http://goo.gl/JnZOeu. Registration from Tuesday onward will be possible via email to bamcc@berkeley.edu, provided space is available.
The symposium is Friday, January 17, 2014 in 245 Li Ka Shing Center.
The meeting will bring together leading scientists from the rapidly emerging field of cancer genomics and provide a unique opportunity to learn about the state of the art in the field.
Speakers
- Samuel Aparicio, BM, BCh, PhD, FRCPath, Nan & Lorraine Robertson Chair in Breast Cancer Research, and Canada Research Chair in Molecular Oncology, University of British Columbia and the BC Cancer Agency
- Luis Diaz, MD, Attending Physician, Johns Hopkins Hospital
- Maria Figueroa, MD, Assistant Professor of Pathology, University of Michigan
- P. Andrew Futreal, PhD, Professor of Genomic Medicine, University of Texas MD Anderson Cancer Center
- David Haussler, PhD, Investigator, Howard Hughes Medical Institute; UCSC Distinguished Professor of Biomolecular Engineering, University of California, Santa Cruz
- Matthew Meyerson, MD, PhD, Professor of Pathology, Harvard Medical School, Dana-Farber Cancer Institute
- Esther Rheinbay, PhD, Postdoctoral Researcher, Massachusetts General Hospital and the Broad Institute
Wednesday, January 8, 2014
Science word clouds
Today I broke down and made a word cloud. But, it's a pretty awesome word cloud. It shows the top 75 words used in my research publications in 2013 (excluding common words).
I used http://www.wordle.net, which is nice because it also has code you can modify yourself. I was also directed to http://www.tagxedo.com, which has the advantage of making word clouds in fun shapes.
What I find interesting about this word cloud is that I was surprised by what I saw, and what I didn't see. I was surprised to see "genes" be the top word, because my recent projects, and much of my focus in graduate school, was on intergenic regions. Turns out, though, that 2013 was my year for genes.
I was also surprised at first that I didn't see "Y" or "X", but then realized that I asked the program to ignore common words, which probably includes all single letters also. I was happy to note that "X-Y" is in there, and so are "X-linked", "Y-linked", and "XAR".
If I can remember, this seems like a fun annual tradition to reminisce about the projects published in the previous year. Given that it can sometimes be months or over a year from the completion of a project until its publication, this is definitely a different snapshot, than if I were to use text from the projects I'm currently working.
Wordle allows you to save your images in a public gallery, so feel free to share your 2013 word cloud in the comments! I'm also happy to update this with other word cloud generation software or codes that you share in the comments.
 |
| M. Wilson Sayres' 2013 research publication word cloud. |
I used http://www.wordle.net, which is nice because it also has code you can modify yourself. I was also directed to http://www.tagxedo.com, which has the advantage of making word clouds in fun shapes.
What I find interesting about this word cloud is that I was surprised by what I saw, and what I didn't see. I was surprised to see "genes" be the top word, because my recent projects, and much of my focus in graduate school, was on intergenic regions. Turns out, though, that 2013 was my year for genes.
I was also surprised at first that I didn't see "Y" or "X", but then realized that I asked the program to ignore common words, which probably includes all single letters also. I was happy to note that "X-Y" is in there, and so are "X-linked", "Y-linked", and "XAR".
If I can remember, this seems like a fun annual tradition to reminisce about the projects published in the previous year. Given that it can sometimes be months or over a year from the completion of a project until its publication, this is definitely a different snapshot, than if I were to use text from the projects I'm currently working.
Wordle allows you to save your images in a public gallery, so feel free to share your 2013 word cloud in the comments! I'm also happy to update this with other word cloud generation software or codes that you share in the comments.
Thursday, January 2, 2014
Notes on: A fresh look at the male-specific region of the human Y chromosome
I think that it would be useful or me to take notes on the papers I'm reading, and I figured it might be useful to share them online because, open science and all. These papers will be in my area of study: sex chromosome evolution and sex-biased processes. If you're interested, please go read the paper, and we can have a discussion in the comments. The link to the paper and full citation are found at the bottom. Let's jump right in!
Jangravi et al. (2013) introduce the Chromosome-centric Human Proteome Project (C-HPP), focusing on the Y chromosome (Y-HPP). Their project is scheduled to run over the next 10 years, and they state that "the objective of Y-HPP is to map and annotate all proteins encoded by genes on the MSY sequences." In this, Jangravi et al. (2013) give an excellent overview of the Y chromosome, contribute new synthesis of previous work, and describe the plans for their group's project.
As background, the male specific region of the Y (MSY) is composed of three broad regions, originally described together by Skaletsky et al (2003):
Some notes from the paper:
Jangravi et al. (2013) introduce the Chromosome-centric Human Proteome Project (C-HPP), focusing on the Y chromosome (Y-HPP). Their project is scheduled to run over the next 10 years, and they state that "the objective of Y-HPP is to map and annotate all proteins encoded by genes on the MSY sequences." In this, Jangravi et al. (2013) give an excellent overview of the Y chromosome, contribute new synthesis of previous work, and describe the plans for their group's project.
As background, the male specific region of the Y (MSY) is composed of three broad regions, originally described together by Skaletsky et al (2003):
- X-degenerate region (relics of the ancestral sex chromosomes)
- X-transposed region (transposed from the X to the Y after chimpanzee-human divergence)
- Ampliconic region (repetitive region, mostly acquired from the autosomes)
Some notes from the paper:
- There are 60 unique genes (loci) on the male-specific region (MSY) of the Y chromosome, but there is not yet reliable protein evidence for 20 of these. This means that, although the DNA sequence seems like it should make a functioning product, and we have evidence of transcripts for most of these, we have not yet observed whether a protein is made. Not making a protein doesn't necessarily mean the gene is non-functional.
- "Of the MSY proteins, 16.0% do not have a known molecular function."
- "The sub cellular localizations of 25.0% of proteins remains undescribed."
- "About 15% of all XY sex-reversed individuals have been known to carry SRY mutations."
- "...SRY causes differentiation of pre-Sertoli cells to produce a testis and suppress genes that favor the formation of the female gonad" starting at 7 weeks of development.
- Sertoli cell-only syndrome, a condition characterized by the presence of complete Sertoli cells in the testes but a lack of spermatozoa in the ejaculate, results from mutations in DDX3Y and USP9Y. DDX3Y (an ATP-dependent RNA helicase) and USP9Y (encodes a protease with activity specific to ubiquitin and is involved in the regulation of protein metabolism (protein turnover)).
- One in six prostate cancer specimens showed at least some Y chromosome-specific genes lost in most specimens. Especially interesting (to me) is that decreased (< 20) copy number of TSPY is associated with increased incidence of prostate cancer.
- A database of protein interactions of Y-linked genes available in the PPI section of the Human Y chromosome Proteome Database: http://www.hupo.ir. This will be very useful, especially as they add more to it.
- Post-translational modifications (modifications made to the protein that we cannot currently predict from the DNA sequence of the gene) are still poorly understood. For the Y-linked gene DDX3Y at least 67 post-translational modifications have been identified, falling into five types: phosphorylation, deamination, acetylation, ubiquitination, and methylation. I'm really curious what the effects of all of these are.
J Proteome Res. 2013 Jan 4;12(1):6-22. doi: 10.1021/pr300864k. Epub 2012 Dec 20.
A fresh look at the male-specific region of the human Y chromosome.
Jangravi Z, Alikhani M, Arefnezhad B, Sharifi Tabar M, Taleahmad S, Karamzadeh R, Jadaliha M, Mousavi SA, Ahmadi Rastegar D, Parsamatin P, Vakilian H, Mirshahvaladi S, Sabbaghian M, Mohseni Meybodi A, Mirzaei M, Shahhoseini M,Ebrahimi M, Piryaei A, Moosavi-Movahedi AA, Haynes PA, Goodchild AK, Nasr-Esfahani MH, Jabbari E, Baharvand H,Sedighi Gilani MA, Gourabi H, Salekdeh GH.